Coordination
Coordination is probably the best word for this, as it encompasses orchestration in both a distributed and local manner. Distributed coordination is infinitely harder than local coordination, but they all use the same primitives for consistency, ordering, and sequential history. Distributed database locks, Airflow DAG's, RAFT based data consistency, etc all revolve around some coordinated effort to do something, and instead of going into all of those mostly want to cover the coordination services in control planes that make this possible
Apache Zookeeper
Zookeeper is one of the first things that pops up when discussing distributed coordination / metadata / configurations. It's defined as "ZooKeeper is a distributed, open-source coordination service for distributed applications. It exposes a simple set of primitives that distributed applications can build upon to implement higher level services for synchronization, configuration maintenance, and groups and naming"
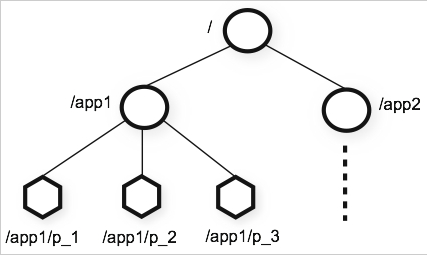
Zookeeper is focused on building a set of primitives so that distributed coordination services are "easy" and don't fall into traps around race conditions or deadlocks. Zookeeper utilizes a shared hierarchical namespace similar to a file directory, but each level can store metadata, namespace configurations, etc, so it's more akin to a N-ary Tree where each node can have any number of children. This namespace itself is comprised of ZNodes which are similar to files and directories. Each time a ZNode's data changes, the version number increases, and so any client knows whether or not it has the most up to date configuration / version information
Zookeeper is high performance via keeping ZNode information in-memory, but ensures high availability and strict ordering which allows it to avoid being a single point of failure. Zookeeper is replicated across a set of hosts called an ensemble - and so the hosts / servers that make up Zookeeper must all know about each other, and maintain an in-memory image of state, transaction logs, and snapshots in a persistent store. Clients can connect to any of the hosts in an ensemble, and each of the hosts is connected to a Zookeeper Leader
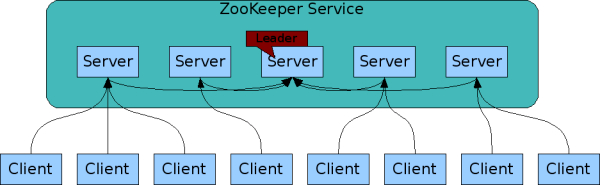
Zookeeper keeps it's ordering by utlizing a stamped number reflecting the order of all zookeeper transactions, where subsequent operations can use the order to implement higher level abstractions and synchronization primitives. This causes some global locking to ensure a serializable order (that is sequential), and so Zookeeper is best for read-dominant workloads. The documentation mentions is performs best when reads are more common than writes, at a minimum ratio of 10:1
Watches and conditional updates are also available for znode's, and they are similar to event based notifications. Watches are triggered and removed when a znode changes, and when triggered it sends a notificaiton to the client saying the znode has changed
Vocabulary:
- ZNode: A node in the hierarchical namespace
- Emphemeral nodes exist as long as the session that creates the znode is active, and is deleted once that session is over
- Ensemble: A set of servers with a leader and many replicas to serve client requests
- Watch: Notification if a znode updates / changes
Implementation
The core of zookeeper is made up of a few components:
- Request processor
- Replicated database: An in memory database containing the entire tree data, where updates are logged to disk, and writes serialized to disk before being applied to the in-memory database
- Messaging layer: An atomic and consensus based protocol to ensure that state doesn't diverge between leaders and followers. "ZooKeeper uses a custom atomic messaging protocol. Since the messaging layer is atomic, ZooKeeper can guarantee that the local replicas never diverge. When the leader receives a write request, it calculates what the state of the system is when the write is to be applied and transforms this into a transaction that captures this new state."
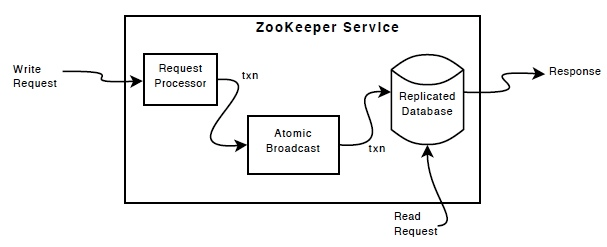
To ensure fault tolerance and recoverability, data needs to be written to disk - "The replicated database is an in-memory database containing the entire data tree. Updates are logged to disk for recoverability, and writes are serialized to disk before they are applied to the in-memory database."
To ensure consistency, Zookeeper uses a RAFT / Consensus style protocol for writes, so any replica / follower can receive a write, but only the leader / primary node can propose changes. There's a messaging layer that takes care of replacing leaders on failure, and syncing followers with leaders. The reliability